Log analysis experiment
I’ve been playing lately with logstash using data from the ulogd JSON output plugin and the Suricata full JSON output as well as standard system logs.
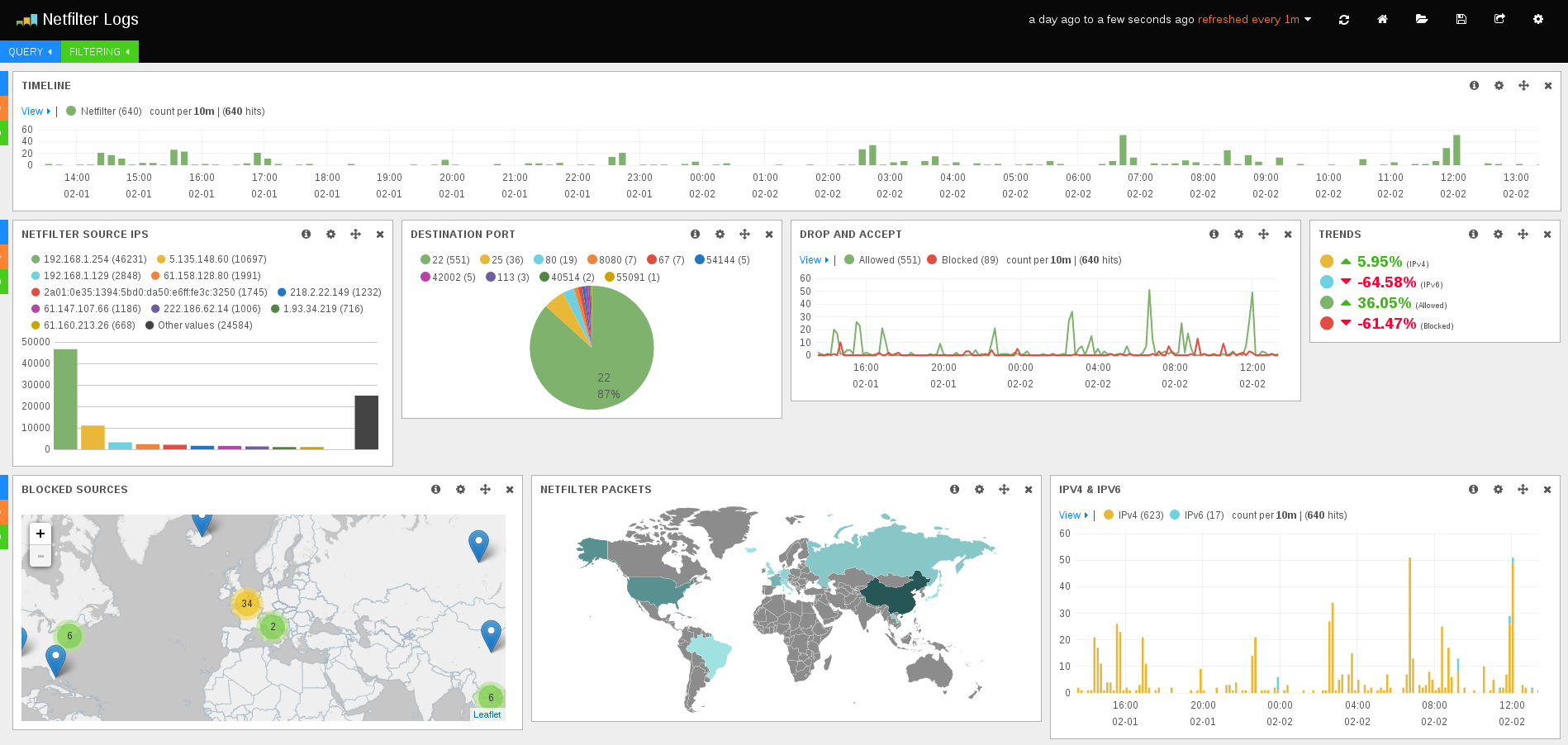
Ulogd is getting Netfilter firewall logs from Linux kernel and is writing them in JSON format. Suricata is doing the same with alert and other traces. Logstash is getting both log as well as sytem log. This allows to create some dashboard with information coming from multiple sources. If you want to know how to configure ulogd for JSON output check this post. For suricata, you can have a look at this one.
Ulogd output is really new and I was experimenting with it in Kibana. When adding some custom graphs, I’ve observed some strange things and decided to investigate.
Displaying TCP window
TCP window size at the start of the connection is not defined in the RFC. So every OSes have choozen their own default value. It was thus looking interesting to display TCP window to be able to find some strange behavior. With the new ulogd JSON plugin, the window size information is available in the tcp.window key. So, after doing a query on tcp.syn:1 to only get TCP syn packet, I was able to graph the TCP window size of SYN packets.
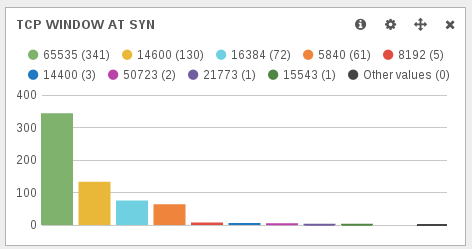
Most of the TCP window sizes are well-known and correspond to standard operating systems:
- 65535 is or MacOSX or some MS Windows OS.
- 14600 is used by some Linux.
The first uncommon value is 16384. Graph are clickable on Kibana, so I was at one click of some interesting information.
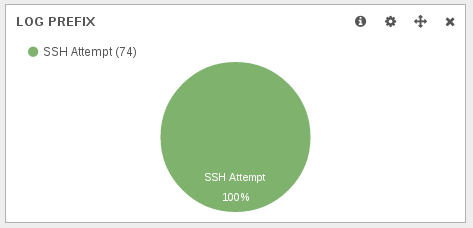
First information when looking at dashboard after selection TCP syn packet with a window size of 16384 was the fact, it was only ssh scanning:
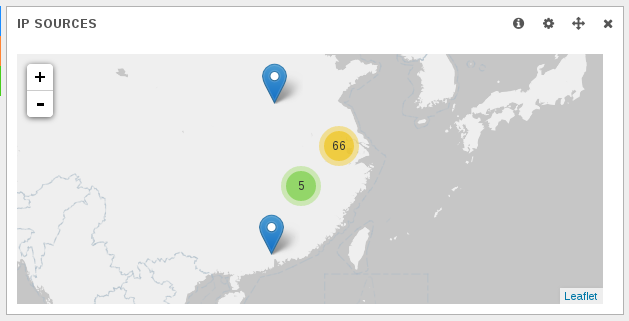
Second information is the fact that, according to geoip, all IPs are chinese:
A SSH scanning software
When looking at the details of the attempt made on my IP, there was something interesting:
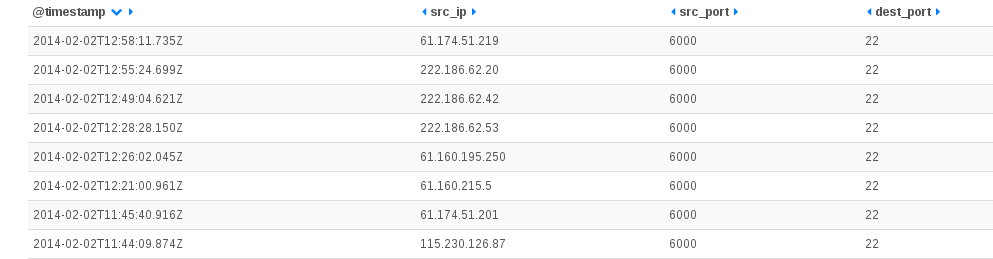
For all hosts, all requests are done with the same source port (6000). This is not possible to do that with a standard ssh client where the source port is by default choosen by the operating system. So or we have a custom standard software that perform a bind operation to port 6000 at socket creation. This is possible and one advantage would be to be easily authorized through a firewall if the country had one. Or we could have a software developped with low level (RAW) sockets for performance reason. This would allow a faster scanning of the internet by skipping OS TCP connection handling. There is a lot of posts regarding the usage of port 6000 as source for some scanning but I did not find any really interesting information in them.
On suricata side, most of the source IPs are referenced in ET compromised rules:

Analysing my SSH logs, I did not see any trace of ssh bruteforce coming from source port 6000. But when selecting an IP, I’ve got trace of brute force from at least one of the IP:
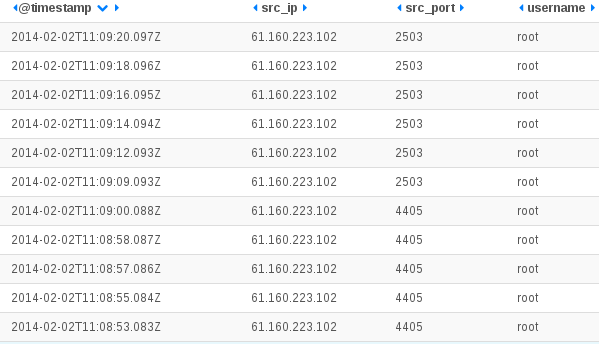
These attackers seems to really love the root account. In fact, I did not manage to find any trace of attempts for user different than root for IP address that are using the port 6000.
Getting back to my ulogd dashboard, I’ve displayed more info about the used scanning sequence:
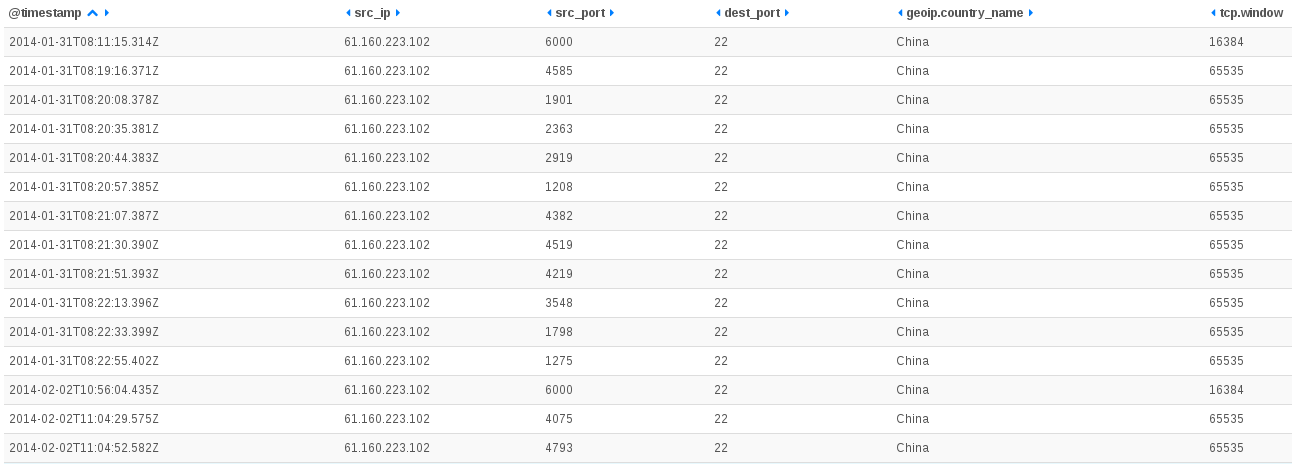
The host scans the box using a scanner using raw socket, then it attacks with a few minutes later with SSH bruteforce tool. The bruteforce tool has a TCP window size at start of 65535. It indicates that a separated software is used for scanning. So we should have an queueing mechanism between the scanner and the bruteforce tool. This may explains the duration between the scan and the bruteforce. Regarding TCP window size value, 65535 seems to indicate a Windows server (which is coherent with TTL value).
Looking at the scanner traffic
Capturing a sample traffic did not give to much information. This is a scanner sending a SYN and cleanly sending a reset when it got the SYN, ACK:
14:27:54.982273 IP (tos 0x0, ttl 103, id 256, offset 0, flags [none], proto TCP (6), length 40)
218.2.22.118.6000 > 192.168.1.19.22: Flags [S], cksum 0xa525 (correct), seq 9764864, win 16384, length 0
14:27:54.982314 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 44)
192.168.1.19.22 > 218.2.22.118.6000: Flags [S.], cksum 0xeee2 (correct), seq 2707606274, ack 9764865, win 29200, options [mss 1460], length 0
14:27:55.340992 IP (tos 0x0, ttl 111, id 14032, offset 0, flags [none], proto TCP (6), length 40)
218.2.22.118.6000 > 192.168.1.19.22: Flags [R], cksum 0xe48c (correct), seq 9764865, win 0, length 0
But it seems the RST packet after the SYN, ACK is not well crafted:

More info on SSH bruteforce tool
Knowing the the behavior was scanning from 6000 and starting a normal scanning, I’ve focused the Suricata dashboard on one IP to see if I had some more information:
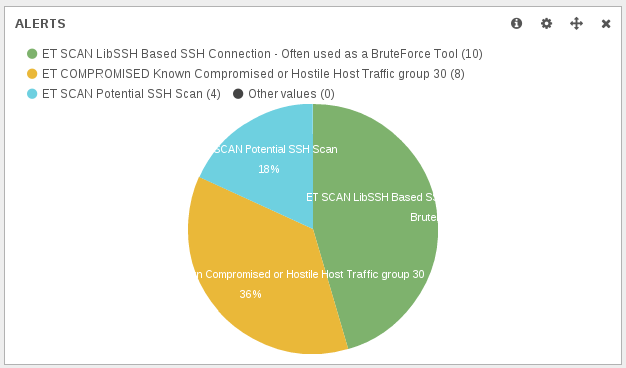
One single IP in the list of the scanning host is triggering multiple alerts. The event table confirmed this:

Studying the geographical repartition of the Libssh alert, it appears there is used in other countries than China:
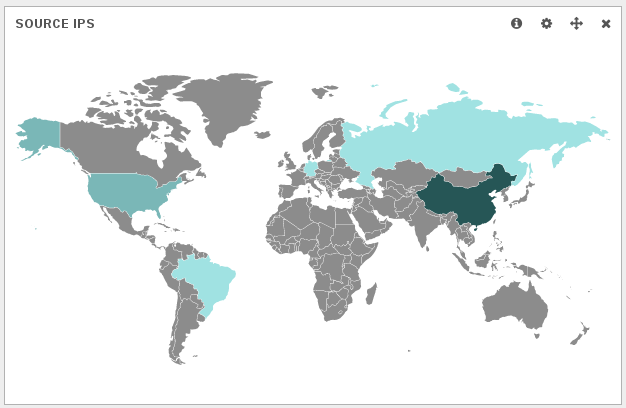
So, libssh is not a discriminatory element of the attacks.
Conclusion
A custom attack tool has been been deployed on some Chinese IPs. This is a combination of a SSH scanner based on RAW socket and a SSH bruteforce tool. It tries to gain access to the root account of system via the ssh service. On an organisational level, it is possible there is a Chinese initiative trying to get the low-hanging fruit (system with ssh root account protected by password) or maybe it is just a some organization using some compromised Chinese IPs to try to get control other more boxes.

