Motivation
I’ve recently met @aurelsec and we’ve discussed about the interest of logging connection tracking entries. This is indeed a undervalued information source in a network.
Quoting Wikipedia: “Connection tracking allows the kernel to keep track of all logical network connections or sessions, and thereby relate all of the packets which may make up that connection. NAT relies on this information to translate all related packets in the same way, and iptables can use this information to act as a stateful firewall.”
Connection tracking being linked with Network Address Translation has a direct impact: it stores both side of each connection. If we use conntrack tool from conntrack-tools to list connections:
# conntrack -L
tcp 6 431999 ESTABLISHED src=192.168.1.129 dst=19.1.16.7 sport=53400 dport=443 src=19.1.16.7 dst=1.2.3.4 sport=443 dport=53500 [ASSURED] mark=0 use=1
...
We have the two sides of a connection:
- Orig: here 192.168.1.129:53400 to 19.1.16.7:443. This is the packet information as seen by the firewall when it reaches him. There is no translation at all.
- Reply: here 19.1.16.7:443 to 1.2.3.4:53500. This is how will look like a answer coming from the server. The destination has been changed to the public IP of the firewall (here
1.2.3.4). And there is also a change of the destination port to the one used by the firewall when doing the initial mapping. In fact, as multiple client could use the same port at the same time, the firewall may have to rewrite the initial source port.
So the connection tracking stores all NAT transformations. This information is important because this is the only way to know which IP in a private network is responsible of something in the outside world. For example, let’s suppose that 19.1.16.7 has been attacked by our internal client (here 192.168.1.129). If the admin of this server sees the attack, it will only see the 1.2.3.4 IP address and port source 53500. If an authority asks you for the IP address responsible in your internal network you have no instrument but the conntrack to know that this was in fact 192.168.1.129.
That’s why logging connection tracking event is one of the only effective way to store the information necessary to get back to the internal IP address in case of external query. Let’s now do this with ulogd 2.
Ulogd setup
Ulogd installation
Ulogd 2 is able to get information from the connection tracking and to log them in files or database.
If your distribution is not providing ulogd and if you don’t know how to install it, you can check this post Using ulogd and JSON output.
To be sure that you will be able to log connection tracking event, you need to have NFCT plugin to yes at the end of configure output.
Ulogd configuration:
Input plugins:
NFLOG plugin: yes
NFCT plugin: yes
Kernel setup
All functionalities are standard since kernel 2.6.14. You only need to load the following module:
modprobe nf_conntrack_netlink
It is the one in charge of kernel and userspace information exchange regarding connection tracking.
It provides features to dump the conntrack table or modify entries in the conntrack. For example the conntrack tool mentioned before is using that communication method to get the listing of connection tracking entries. But the feature that interest us in ulogd is the event mode. For each event in the life of a connection, a message is sent to the userspace. Ulogd is able to listen to these messages and this gives it the ability to store all information on the life of the connection in connection tracking.
Depending on the protocol you have on your network, you may need to run on of the following:
modprobe nf_conntrack_ipv4
modprobe nf_conntrack_ipv6
Ulogd setup
Our first objective will simply be to log all NAT decisions to a syslog-like file on disk. In term of connection tracking, this means we will log all connection in the NEW state. This way we will get information about any packet going through the firewall with the associated NAT transformation.
If you install from sources, copy ulogd.conf at the root of ulogd sources to your config directory (usually /usr/local/etc/. And start your favorite editor on it.
Ulogd is doing logging based on stack definition. A stack is one chain of plugins starting from a input plugin, finishing with an output one, and with filter in the middle. In our case, we want to get packet from Netfilter conntrack and the corresponding plugin is NFCT. The first example of stack containing NFCT in the ulogd.conf file is the one we are interested in, so we uncomment it:
stack=ct1:NFCT,ip2str1:IP2STR,print1:PRINTFLOW,emu1:LOGEMU
We are not sure that the setup of input and output plugin will be correct. For now, let’s just check the output:
[emu1]
file="/var/log/ulogd_syslogemu.log"
sync=1
As you may have seen, emu1 is also used by packet logging. So it may be a good idea that we have our own output file for connection tracking event.
To do that, we update the stack:
stack=ct1:NFCT,ip2str1:IP2STR,print1:PRINTFLOW,emunfct1:LOGEMU
and create a new config below emu1:
[emunfct1]
file="/var/log/ulogd_nfct.log"
sync=1
We have changed file name and keep the sync option which permit to avoid the a delay in write due to buffering effect during write which can be very annoying when debugging a setup.
Now, we can test:
ulogd -v
In /var/log/ulogd_nfct.log, we see things like
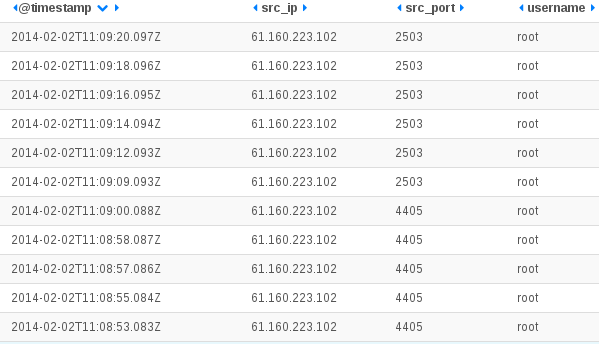
Feb 22 10:50:36 ice-age2 [DESTROY] ORIG: SRC=61.174.51.209 DST=192.168.1.129 PROTO=TCP SPT=6000 DPT=22 PKTS=0 BYTES=0 , REPLY: SRC=192.168.1.129 DST=61.174.51.209 PROTO=TCP SPT=22 DPT=6000 PKTS=0 BYTES=0
So we only have destruction messages. This is not exactly what we wanted to have. We are interested in NEW message that will allow us to have a correct timing of the event. Reading ulogd.conf file, it seems there is no information about chossing the event types. But let’s ask to the NFCT input plugin its capabilities. To do that we use option -i of ulogd:
# ulogd -v -i /usr/local/lib/ulogd/ulogd_inpflow_NFCT.so
Name: NFCT
Config options:
Var: pollinterval (Integer, Default: 0)
Var: hash_enable (Integer, Default: 1)
Var: hash_buckets (Integer, Default: 8192)
Var: hash_max_entries (Integer, Default: 32768)
Var: event_mask (Integer, Default: 5)
Var: netlink_socket_buffer_size (Integer, Default: 0)
Var: netlink_socket_buffer_maxsize (Integer, Default: 0)
Var: netlink_resync_timeout (Integer, Default: 60)
Var: reliable (Integer, Default: 0)
Var: accept_src_filter (String, Default: )
Var: accept_dst_filter (String, Default: )
Var: accept_proto_filter (String, Default: )
...
The listing start with the configuration keys. One of them is event_mask. This is a the one controlling which events are sent from kernel to userspace.
The value is a mask combining some of the following values:
- NF_NETLINK_CONNTRACK_NEW: 0x00000001
- NF_NETLINK_CONNTRACK_UPDATE: 0x00000002
- NF_NETLINK_CONNTRACK_DESTROY: 0x00000004
So default value of 5 is to listen to NEW and DESTROY events.
Clever reader will then ask: why did we only see DESTROY messages in that case. This is because ulogd NFCT plugin is running by default in hash_enable mode. In this mode, one single message is output for each connection (at end) and a hash is maintained in the kernel to store the info (here initial timestamp of the connection).
Our setup don’t need this feature because we only want to get the NAT transformation so we switch the hash feature off and limit the events to NEW:
[ct1]
event_mask=0x00000001
hash_enable=0
We can now restart ulogd and check the log file:
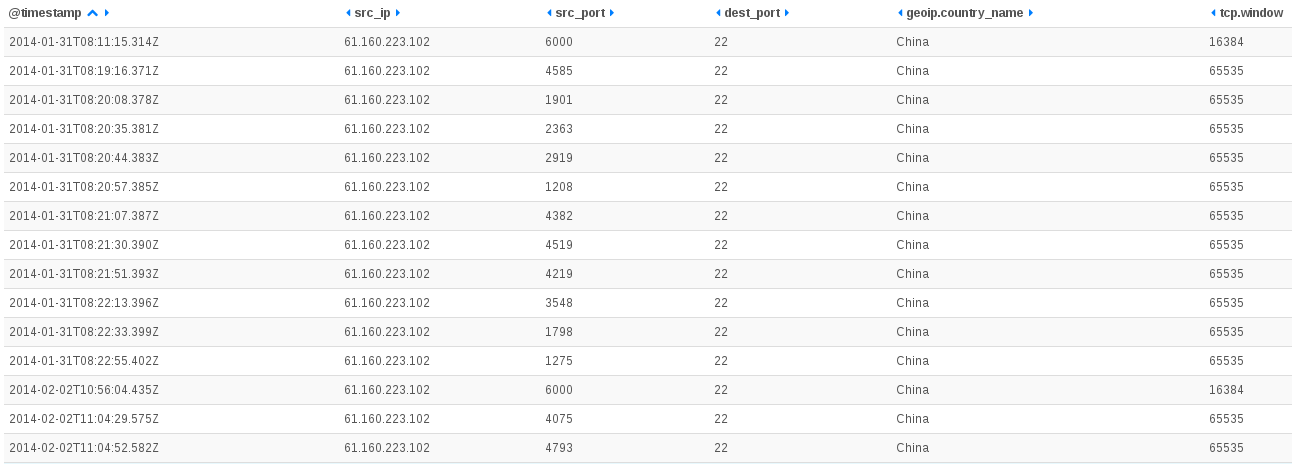
Feb 22 11:59:34 ice-age2 [NEW] ORIG: SRC=2a01:e35:1394:5bd0:da50:b6ff:fe3c:4250 DST=2001:41d0:1:9598::1 PROTO=TCP SPT=51162 DPT=22 PKTS=0 BYTES=0 , REPLY: SRC=2001:41d0:1:9598::1 DST=2a01:e35:1394:5bd0:da50:b6ff:fe3c:4250 PROTO=TCP SPT=22 DPT=51162 PKTS=0 BYTES=0
Feb 22 11:59:43 ice-age2 [NEW] ORIG: SRC=192.168.1.129 DST=68.232.35.139 PROTO=TCP SPT=60846 DPT=443 PKTS=0 BYTES=0 , REPLY: SRC=68.232.35.139 DST=1.2.3.4 PROTO=TCP SPT=443 DPT=60946 PKTS=0 BYTES=0
This is exactly what we wanted, we have a trace of all NAT transformation.
Maintain an history of connection tracking
Objective
We want to log all information describing a connection so we have a trace of what is going on the firewall. This means we need at least:
- IP information for orig and reply way
- Timestamp of start and end of connection
- Bandwidth used by the connection
Kernel setup
By default, recent kernel have a limited handling of connection tracking. Some useful fields are not stored for performance reason. This is the case of the accounting (number of packets and bytes) and the case of the timestamp of the connection creation. The advantage of getting accounting information is trivial as you get information on bandwidth usage. Regarding timestamp, the interest is on implementation side. It allows ulogd to get all information needed for describing a connection in one single message (the DESTROY one). And ulogd does not need anymore to maintain a hash table to get the info and propagate it at exit.
To activate both features, you have to do:
echo "1"> /proc/sys/net/netfilter/nf_conntrack_acct
echo "1"> /proc/sys/net/netfilter/nf_conntrack_timestamp
Ulogd setup
For following setup, you will need ulogd build from git or a ulogd at a version superior or equal to 2.0.4.
Let’s first use JSON output to get the information in a readable format. We need to define a stack:
stack=ct2:NFCT,ip2str1:IP2STR,jsonnfct1:JSON
On ct2 side, we don’t want to use the hash and we only want to get DESTROY message, so our configuration looks like:
[ct2]
hash_enable=0
event_mask=0x00000004
Regarding, jsonnfct1 we could have reused the default JSON configuration but for ease of testing we will dedicate a file to the NFCT logging:
[jsonnfct1]
sync=1
file="/var/log/ulogd_nfct.json"
After a ulogd restart, we’ve got this type of entries:
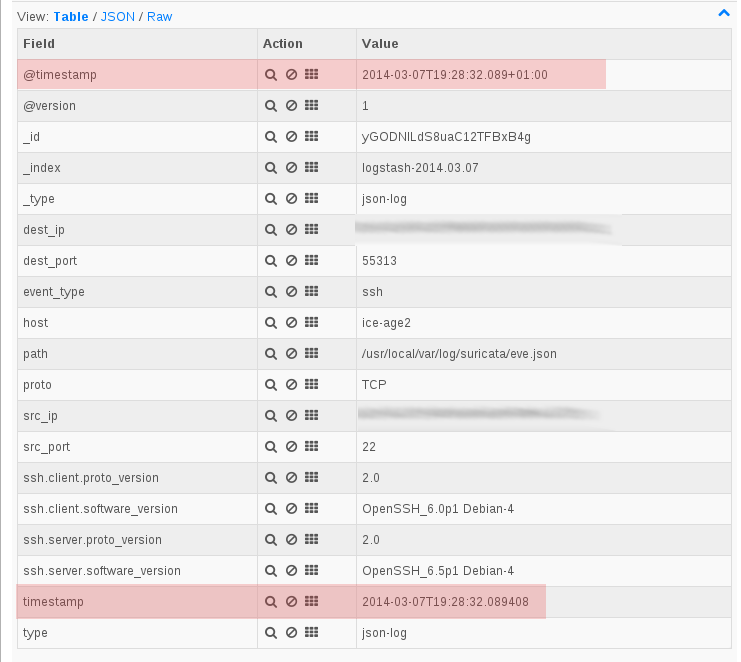
{"reply.ip.daddr.str": "2a01:e35:1394:5ad0:da50:e6ff:fe3c:1250", "oob.protocol": 0, "dvc": "Netfilter", "timestamp": "Sat Feb 22 12:27:04 2014", "orig.ip.protocol": 6, "reply.raw.pktcount": 20, "flow.end.sec": 1393068424, "orig.l4.sport": 51384, "orig.l4.dport": 22, "orig.raw.pktlen": 5600, "ct.id": 1384991512, "orig.raw.pktcount": 23, "reply.raw.pktlen": 4328, "reply.ip.protocol": 6, "reply.l4.sport": 22, "reply.l4.dport": 51384, "ct.mark": 0, "ct.event": 4, "flow.start.sec": 1393068302, "flow.start.usec": 637516, "flow.end.usec": 403240, "reply.ip.saddr.str": "2001:41d0:1:9598::1", "oob.family": 10, "src_ip": "2a01:e35:1394:5ad0:da50:e6ff:fe3c:1250", "dest_ip": "2001:41d0:1:9598::1"}
The fields we wanted are here:
- flow.start.* keys store the timestamp of flow start
- flow.end.* keys store the end of the connection
- *.raw.pkt* keys store the accounting information
You can then add this file to the file parsed by logstash. For that if you can use information from Using ulogd and JSON output and modify the input section:
input {
file {
path => [ "/var/log/ulogd.json", "/var/log/ulogd_nfct.json"]
codec => json
}
}
One interesting information in a connection tracking entry is the duration. But the field is not available in ulogd JSON output and it is not possible to do mathematical operations in Kibana. A solution to get the information is to add a filter in logstash.conf to compute the duration:
filter {
if [type] == "json-log" {
ruby {
code => "if event['ct.id']; event['flow.duration.sec']=(event['flow.end.sec'].to_i - event['flow.start.sec'].to_i); end"
}
}
}
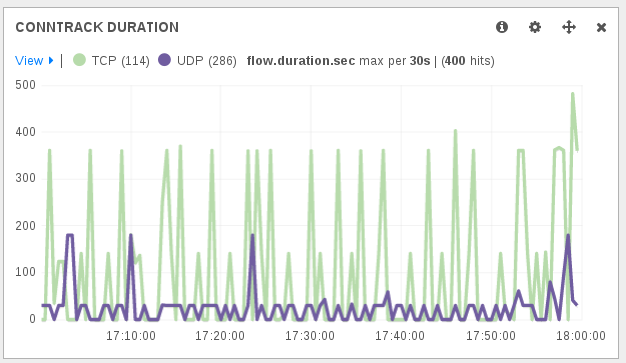
A thing to notice to understand the obtained duration is that a connection is dying following contextual timeout. For example, in the case of a TCP connection, even after a FIN packet there’s a timeout applied. So a short connection will at least be of the duration of the timeout.
An other logging method is PostgreSQL. The stack to use is almost the same as JSON one but use, as you may have guess, the PGSQL plugin:
stack=ct2:NFCT,ip2str1:IP2STR,pgsql2:PGSQL
The configuration of the PostgreSQL plugin is easy based on the setup available in the configuration:
[pgsql2]
db="nulog"
host="localhost"
user="nupik"
table="ulog2_ct"
#schema="public"
pass="changeme"
procedure="INSERT_CT"
I’m not the one who will explain how to connect to a PostgreSQL database and create a ulogd2 database. See Pollux post for that: ulogd2: the new userspace logging daemon for netfilter/iptables (part 2)
Other setup are possible. For example, you can maintain a copy of the connection tracking table in the database and also keep the history.
To do that you need to use the INSERT_OR_REPLACE_CT procedure and a connection tracking INPUT plugin not using the hash table but getting NEW and DESTROY events:
stack=ct2:NFCT,ip2str1:IP2STR,pgsql2:PGSQL
[ct2]
hash_enable=0
[pgsql2]
db="nulog"
host="localhost"
user="nupik"
table="ulog2_ct"
#schema="public"
pass="changeme"
procedure="INSERT_OR_REPLACE_CT"
Connection will be inserted in the table when getting the NEW event and the connection entry in the database will be updated when the DESTROY message will be received.

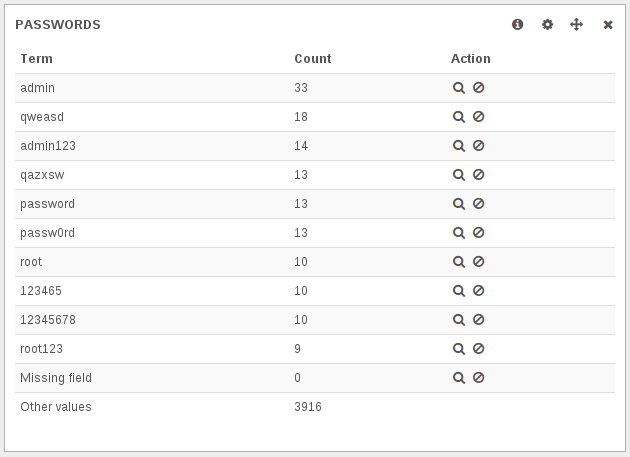
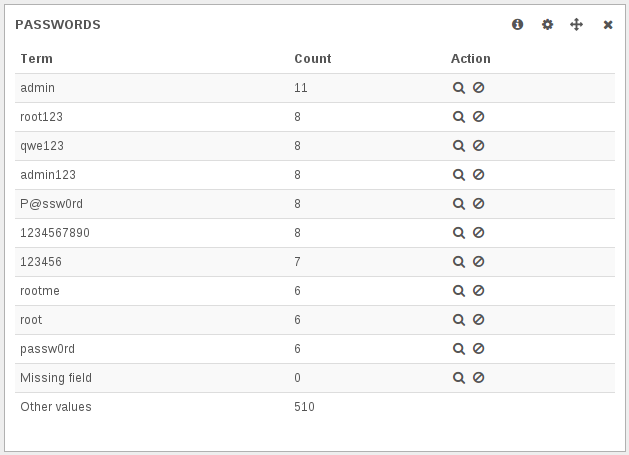
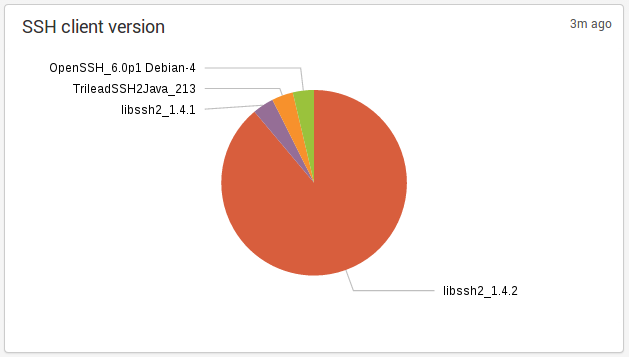
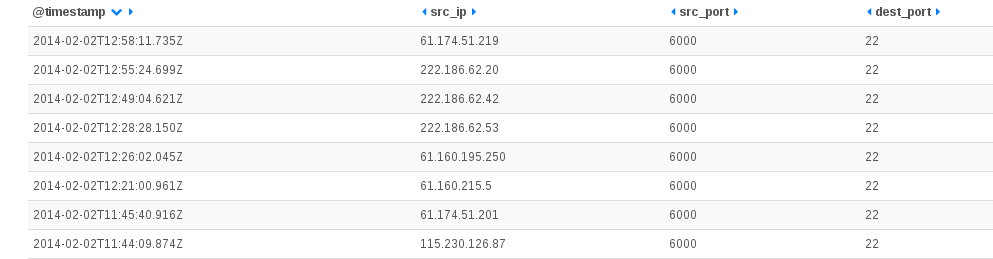



{kind=link}